“GitOps”和“服务网格”可能不是你立即想到的东西 - 但也许它们应该是!这两种截然不同的技术各自具有巨大的独立能力,并且它们结合起来提供的远远超过它们各部分的总和。在这篇博文中,我将向您介绍在现实世界中同时使用 Flux、Flagger 和 Linkerd 以实现成功的 GitOps 需要了解的内容。
我们为什么在这里?
不过,首先,让我们谈谈在静态文本博客文章的结构中我们能做什么和不能做什么。这篇文章本身不会让你成为 GitOps 专家。GitOps 很复杂,实践没有实际的替代品。你不能通过阅读博客文章来获得这一点。
不过,我们在这里可以提供的是仔细研究使 GitOps 实际工作的好、坏和丑陋。我们将讨论概念和惯例,讨论哪些有效,哪些无效,我们将使您能够充分利用您以后投入的实践
最后,不要忘记我们有一个现成的演示存储库供您练习!您可以在 https://github.com/BuoyantIO/gitops-linkerd 中找到它 - 查看其 README.md 以获取完整说明。
GitOps 简介
如果你是 GitOps 的新手,你可能会发现所有关于“持续部署”和“单一不可变事实来源”的定义都令人困惑。出于我们的目的查看 GitOps 的一种简单方法是,这是一种管理集群配置的方法,方法是将我们想要的配置放在 git 存储库中,然后拥有使集群与存储库匹配的软件。
换句话说,您不会通过运行 kubectl apply 来更改集群:使用 Git 提交来进行更改。
这似乎是一种倒退,但这是完成生产中非常重要的两件事的绝佳方式:
- 您始终可以确切地知道您的集群正在运行什么配置。
- 您始终可以知道谁进行了特定更改。
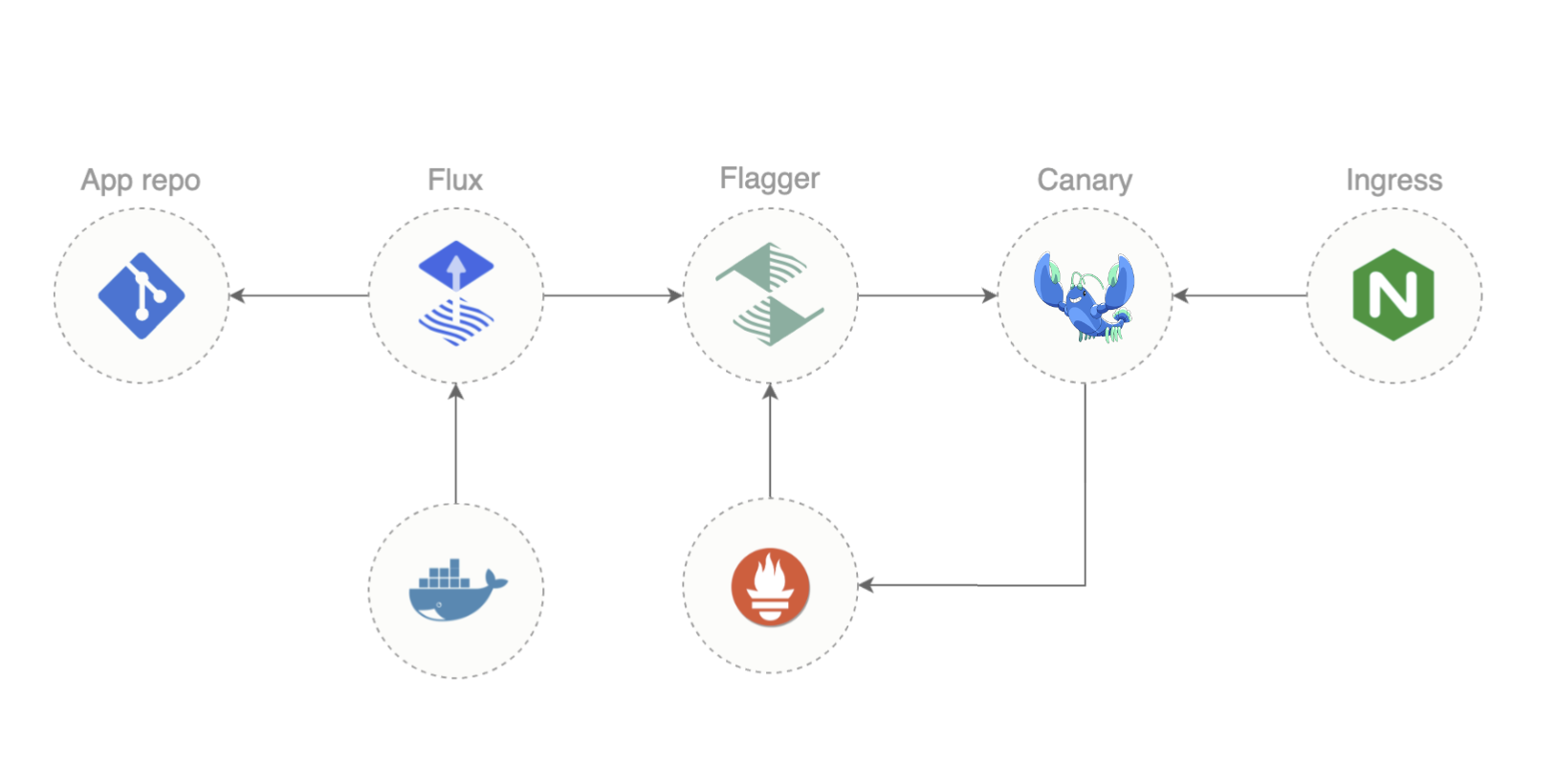
这两件事为许多好东西打开了大门,因为了解集群的状态意味着您可以轻松复制它。知识就是力量。在引擎盖下,我们将使用来自WeaveWorks的Flux和Flagger来完成这项工作。
Flux
Kubernetes 集群无法与 git 存储库进行本机交互。Flux 是一种弥合差距的工具:Flux 代理在群集中运行,并监视存储库和群集中的更改。每当它注意到更改(在任一位置)时,它都会执行任何需要执行的操作以使群集看起来像存储库。
注意:Flux 只会使集群看起来像存储库。没有规定走另一个方向,因为这将是一个糟糕的主意!GitOps 的全部意义在于 git 存储库包含您想要的状态的真相,因此允许存储库修改它不会是一种反模式。
Flux 相当简单:它可以从 GitHub 或 GitLab 读取 Git 存储库,并将其指向存储库中的目录,该目录包含定义 Flux Kustomization 的 YAML 文件。库造口定义包括三个关键组件:
- 源告诉 Flux 去哪里读取集群中应该存在的基本资源。源可以是 Git 存储库或 Helm 图表中的目录。
- 一组可选的补丁(标准 JSONpatch 定义)告诉 Flux 如何在将基本资源应用于集群之前对其进行修改。
- 一个可选的依赖项列表告诉 Flux 在应用此依赖项之前必须应用哪些其他 Kustomization。
这三者的组合非常强大,同时相对简单(尽管我将是第一个承认JSONpatch并不总是令人愉快的使用)。稍后,我们将深入探讨如何处理 Kustomization,以及典型的 Kustomization 可能是什么样子。
Flagger
Flagger是Flux的姊妹篇,专门处理渐进式交付。这个想法是,当您部署工作负载的新版本时,您应该慢慢地将流量增加到它以确保新版本能够正常工作,而不是立即将所有流量削减到新的(可能损坏的)版本。
Flagger最初看起来很奇怪的是,您没有明确提供“请立即进行渐进式推出”的资源。相反,您只需编辑一个部署,Flagger 就会从那里获取它:它会注意到对其管理下的对象的任何更改,并自动调整集群中的内容以设置渐进式部署。
这意味着 Flagger 需要一种方法来控制流向新版本的流量。它不会直接执行此操作:相反,它需要更改系统其他部分的配置以实际进行流量转移。Flagger对此有几种不同的选择:
- 对于调用图顶部的工作负载,它可以直接与多个入口控制器一起使用;
- 它可以对调用图中任何位置的流量使用 SMI 流量拆分;或
- 它可以使用Gateway API HTTPRoutes。
(目前,Linkerd依赖于SMI TrafficSplit机制。稍后会详细介绍。
Linkerd
如果您之前没有运行过 Linkerd,它是一个服务网格:一个在平台级别提供安全性、可靠性和可观测性功能的基础结构层,而无需修改您的应用程序。事实上,它是目前唯一的 CNCF 分级服务网格,可提供出色的安全性、一流的操作简便性和任何生产服务网格中最小的开销。
与大多数其他网格一样,Linkerd 的工作原理是在每个工作负载容器旁边放置一个 sidecar 代理,并允许 sidecar 拦截进出工作负载的所有流量。这种低级访问使 Linkerd 能够对集群中网络通信的情况进行巨大的控制和可见性。
Linkerd 同时支持 SMI TrafficSplit 资源和(从 2.12 开始)网关 API HTTPRoute 资源。但是,在 2.12 和 2.13 中,Linkerd 的 HTTPRoute 支持是有限的,这意味着 Flagger 需要使用 SMI TrafficSplit 接口。
付诸实践:Flux
与许多事情一样,从基本理论到实际实践的跳跃可能很棘手。一个好的开始方法是使用上面提到的演示存储库,https://github.com/BuoyantIO/gitops-linkerd。它的 README.md 提供了有关如何运行一切的完整说明,但让我们在这里也了解亮点和陷阱。
首先,您需要有一个空集群、一个有效的 kubectl 命令和 flux CLI。查看 https://fluxcd.io/flux/installation/ 以获取完整说明,但在 Mac 和 Linux 上的简单方法是 brew install fluxcd/tap/flux 。
存储库布局和 flux bootstrap
需要了解的非常重要的一点是,在使用 Flux 时,您通常会设置所有 Kustomization,将 Flux 安装到本地机器上,然后运行 flux bootstrap 告诉 Flux 为您设置集群中的所有内容!任何时候都不需要手动设置群集。
运行 flux bootstrap 时,您告诉 Flux 要使用的 git 存储库,以及该存储库中的分支和路径,以开始在存储库中查找其配置。这就引出了两个非常重要的点:
- Flux 需要访问你的 Git 存储库,这通常意味着它需要访问 GitHub 或 GitLab,这意味着你需要设置一个访问令牌供 Flux 使用。有关此处的完整详细信息,请查看 https://fluxcd.io/flux/installation/#bootstrap - 但问题是 Flux 需要能够写入和读取(例如,使用 GitHub 需要能够创建部署密钥)。请仔细阅读有关设置令牌的权限的信息。
- 如果你想理解一个 Flux 设置,你需要知道给了 flux bootstrap 什么分支和路径,这样你就会知道从哪里开始阅读以了解发生了什么。
在这篇博文中,我们不会包含 gitops-linkerd 的完整 flux bootstrap 命令:我们希望专注于概念和陷阱,而不是设置 Git 权限等的所有细节。查看 gitops-linkerd 存储库中的 README.md ,了解所有引导程序详细信息。
但是,在我们的 gitops-linkerd 存储库配置中非常值得一看。其配置的起点是 main 分支上的 clusters/my-cluster 目录,你将在其中找到群集基础结构所需的所有定义以及对应用程序本身的另一个存储库的引用。如果要将其用于自己的 Flux/Flagger/Linkerd 设置,一个好的开始是保留群集基础结构,但将应用程序定义替换为您自己的定义。
- infrastructure.yaml 告诉 Flux 要设置的集群基础架构;
- apps.yaml 告诉 Flux 我们想要在该基础架构上运行的应用程序;和
- flux-system 是自定义 Flux 本身的目录。在这篇博文中,我们不会进入 flux-system ,但很高兴知道它是什么。
“基础架构”和“应用程序”之间的划分是模糊的,而且在很大程度上是约定俗成的,但如果您想使用 gitops-linkerd 作为您自己的集群定义的基础,您可以先关注 apps.yaml ,而不考虑集群基础设施。
gitops-linkerd 集群基础架构
infrastructure.yaml 为群集基础结构定义了五个单独的组件。其中每个都由此 YAML 文件中的单独文档表示:
- cert-manager
- Linkerd
- NGINX
- Flagger
- Weave GitOps
(回想一下,Flux本身是我们唯一手动安装的东西。此外,Weave GitOps 是 Flux 的仪表板;在 https://www.cncf.io/blog/2023/04/24/how-to-use-weave-gitops-as-your-flux-ui/ 查看。
重要的是, infrastructure.yaml 还定义了这些组件之间的依赖关系;这是Flux的一个特别强大的方面。我们将在这里快速浏览前两个元素: cert-manager 和 linkerd 。
cert-manager
infrastructure.yaml 中的第一个文档如下所示:
---
apiVersion: kustomize.toolkit.fluxcd.io/v1beta2
kind: Kustomization
metadata:
name: cert-manager
namespace: flux-system
spec:
interval: 1h
retryInterval: 1m
timeout: 5m
prune: true
wait: true
sourceRef:
kind: GitRepository
name: flux-system
path: ./infrastructure/cert-manager
这里有几件事需要了解:
name: cert-manager sets the name of the Kustomization. This is how we’ll refer to this component when describing dependencies.
namespace: flux-system places the Kustomization itself in the flux-system namespace; this does not mean that cert-manager will live in flux-system, though.
按照惯例, flux-system 是群集基础结构核心元素的主页,其他命名空间用于应用程序。
- 没有 dependsOn 属性,因此此库斯托姆化不依赖于任何东西。
- sourceRef 有点神奇:提到 flux-system GitRepository 实际上意味着“与 Kustomization 本身相同的 Git 存储库”。
- path: ./infrastructure/cert-manager 告诉我们在源中的哪个位置查找此 Kustomization 的更多文件。
- wait: true 表示 Flux 将等待安装的所有内容准备就绪,然后再继续其他库Kustomizations。
- interval: 1h 表示 Flux 将每小时检查一次,以查看是否有需要处理的新更改。
如果我们查看 ./infrastructure/cert-manager ,我们会找到一些文件:
kustomization.yaml
namespace.yaml
release.yaml
repository.yaml
开始阅读的地方始终是 kustomization.yaml ,这在这里很简单:
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
namespace: cert-manager
resources:
- namespace.yaml
- repository.yaml
- release.yaml
这会告诉 Flux 应用这三个 YAML 文件。我们不会在这里深入探讨它们 - gitops-linkerd 演示更详细 - 但重要的是要知道
- namespace.yaml 创建 cert-manager 命名空间;
- repository.yaml 告诉 Flux 到 helm repo add 一个 Helm 存储库;和
- release.yaml 告诉 Flux 到 helm install 一个由 repository.yaml 添加的存储库中的图表。
请注意,这实际上是一个无序列表: kustomize 会自动对所有这些文件中包含的所有资源进行排序,以确保它正在使用的资源按正确的顺序应用。
我们将在 gitops-linkerd 演示本身中深入研究这些文件,除了一个注意事项:如果您查看 repository.yaml 和 release.yaml ,您会发现它们在 cert-manager 命名空间中定义资源,而不是 flux-system 命名空间。这是您将一次又一次看到的模式:Kustomization 管理的资源应位于适合所管理组件的命名空间中。
因此,要从中获取的三个重要概念是:
- 您不必在 Kustomization 中应用任何补丁,尽管它的名字。
- 您可以在 Kustomization 中应用 Kubernetes 资源和更高级别的 Flux 资源。
- Kustomization 创建和管理的资源属于组件的相应命名空间,而不是 flux-system 。
当您查看 gitops-linkerd 定义时,您会一遍又一遍地看到这些相同的概念。
The linkerd component
infrastructure.yaml 中的第二个文档定义了 linkerd 个组件:
---
apiVersion: kustomize.toolkit.fluxcd.io/v1beta2
kind: Kustomization
metadata:
name: linkerd
namespace: flux-system
spec:
dependsOn:
- name: cert-manager
interval: 1h
retryInterval: 1m
timeout: 5m
prune: true
wait: true
sourceRef:
kind: GitRepository
name: flux-system
path: ./infrastructure/linkerd
其中大部分与 cert-manager Kustomization 一致:我们有一个 name ,我们仍然在 flux-system 命名空间中,我们会在 ./infrastructure/linkerd 中找到更多文件,等等。
主要区别在于新的 dependsOn 属性,它表示 linkerd Kustomization取决于 cert-manager Kustomization。(另请注意, dependsOn 采用数组值,因此您可以列出许多依赖项。这是 Flux 最强大的功能之一:定义复杂的开始排序只是解释什么取决于什么,然后让 Flux 完成所有艰苦的工作。
快速浏览一下 ./infrastructure/linkerd 目录,我们会发现比 cert-manager 要阅读的内容要多得多:
README.md
ca.crt
ca.key
kustomization.yaml
kustomizeconfig.yaml
linkerd-certs.yaml
linkerd-control-plane.yaml
linkerd-crds.yaml
linkerd-smi.yaml
linkerd-viz.yaml
namespaces.yaml
repositories.yaml
不过,和以前一样,开始阅读的地方仍然是 kustomization.yaml 。它更复杂,因为我们正在安装四个独立的 Linkerd 组件(它的 CRD、控制平面、SMI 扩展和可视化扩展),我们需要将 Linkerd 配置为使用来自 cert-manager 的自定义机密 - 但您将能够看到它们全部布置在文件中。
同样,我们主要将深入探讨留给 gitops-linkerd 演示,但值得指出的是, cert-manager Kustomization 有一个 repository.yaml 文件, linkerd Kustomization 有 repositories.yaml ,名称是复数的。名称对 Flux 来说根本不重要,因为它必须在 kustomization.yaml 中明确列出:这意味着您可以自由选择名称来帮助后来的读者了解正在发生的事情。
infrastructure.yaml 文件中还有很多内容,但我们将把其余部分留给 gitops-linkerd 演示和您自己的阅读。让我们继续使用该应用程序。
https://www.cncf.io/blog/2023/05/25/real-world-gitops-with-flux-flagger-and-linkerd/

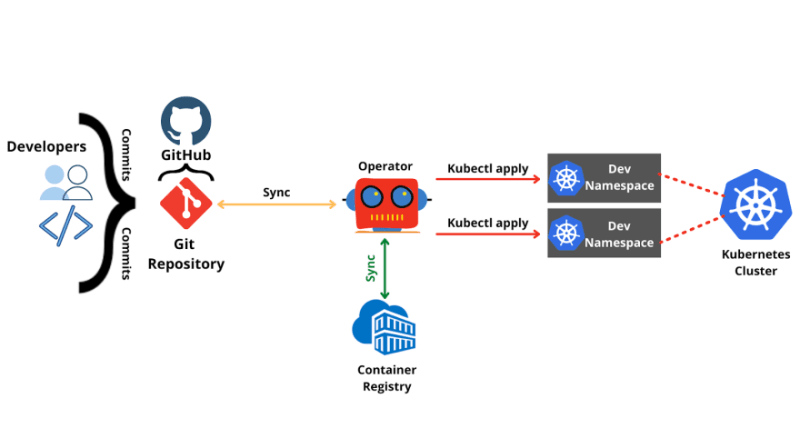

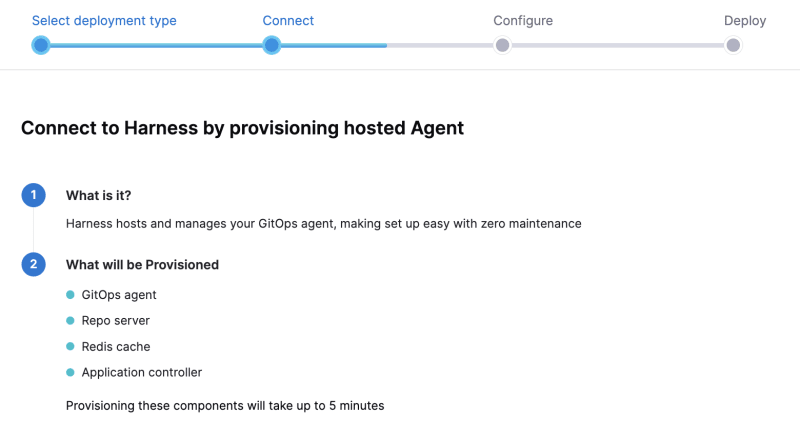
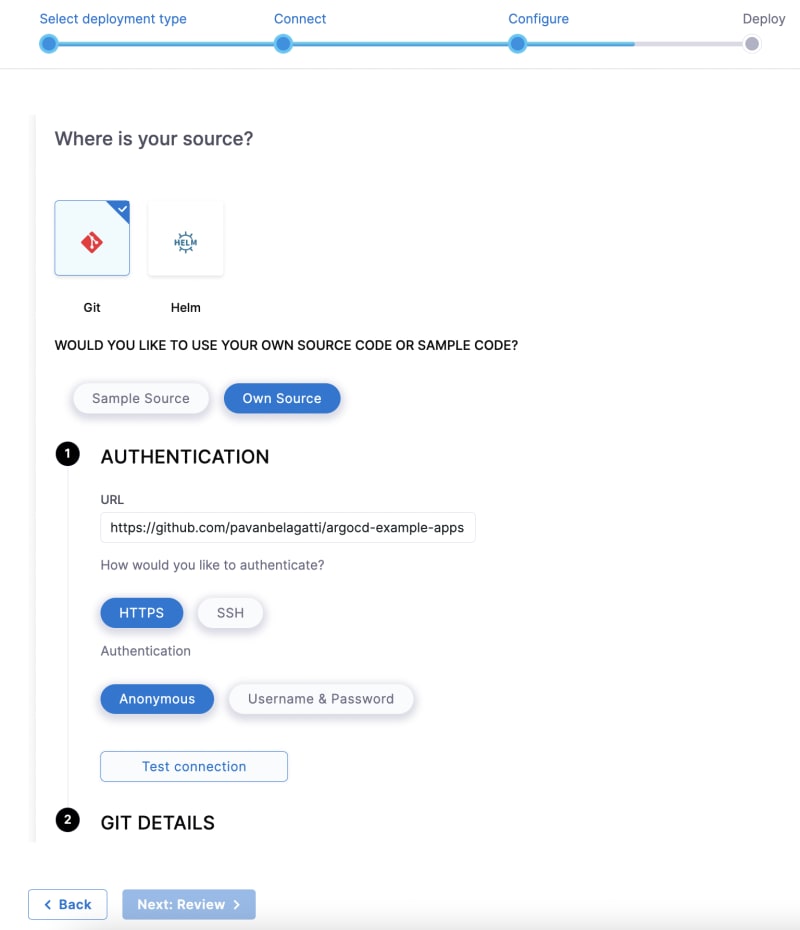
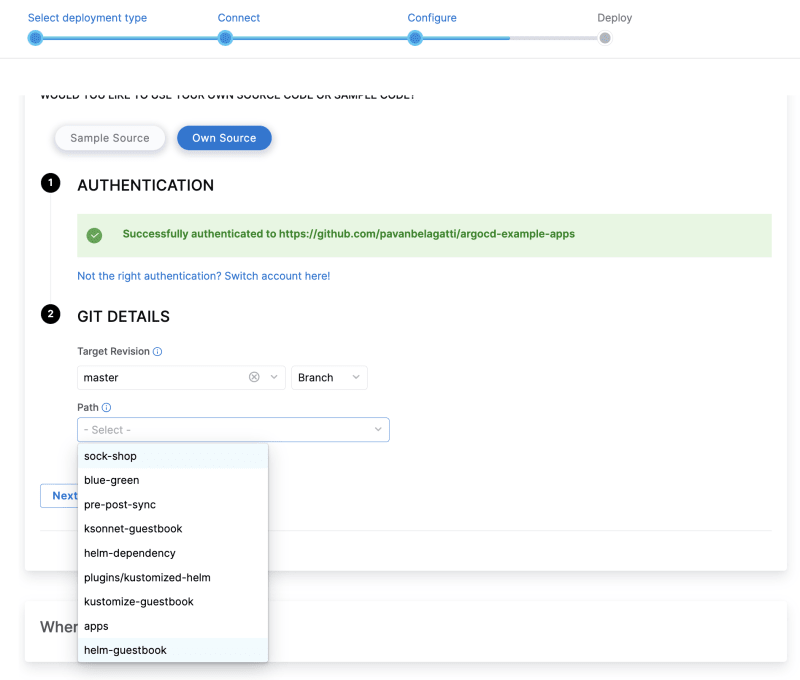
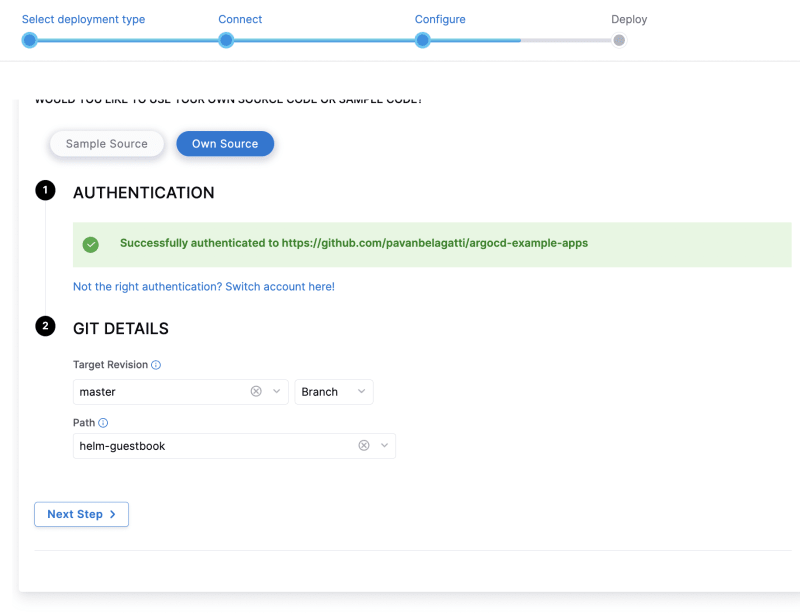
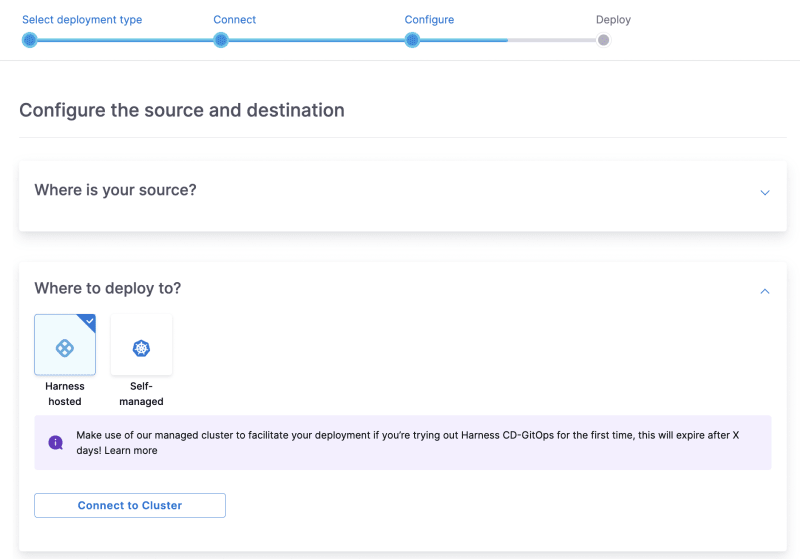
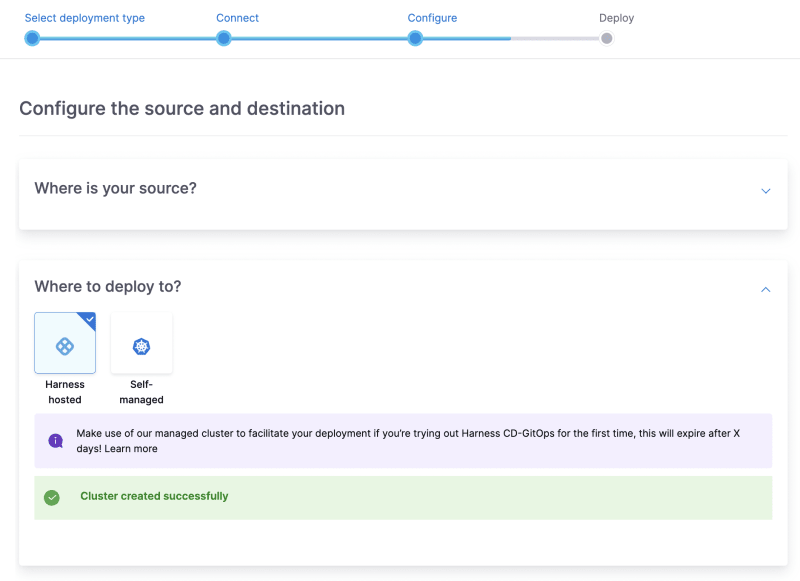
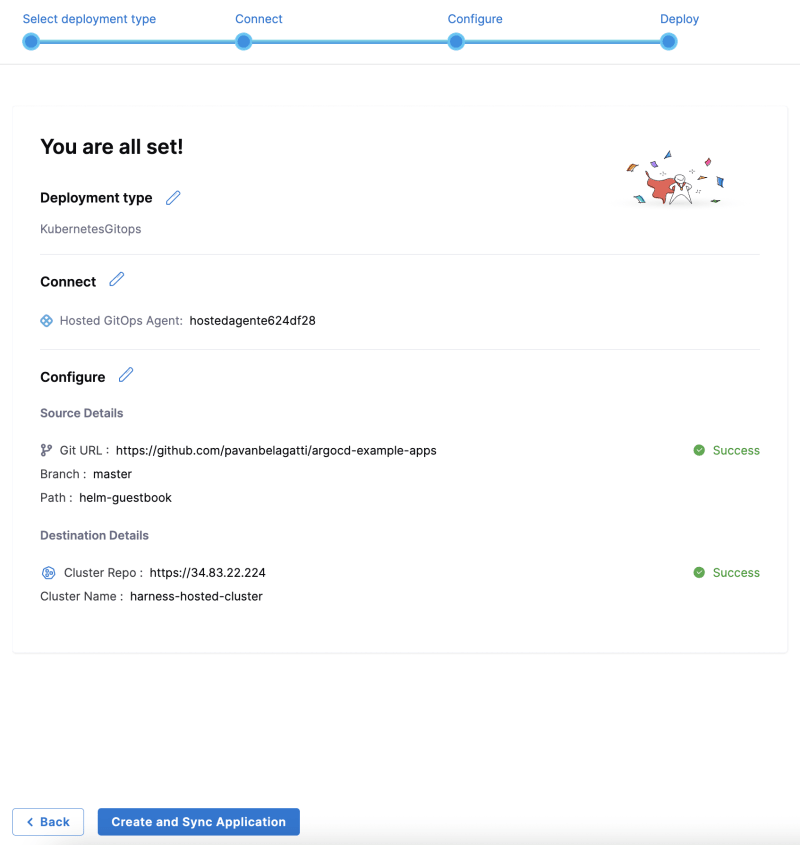
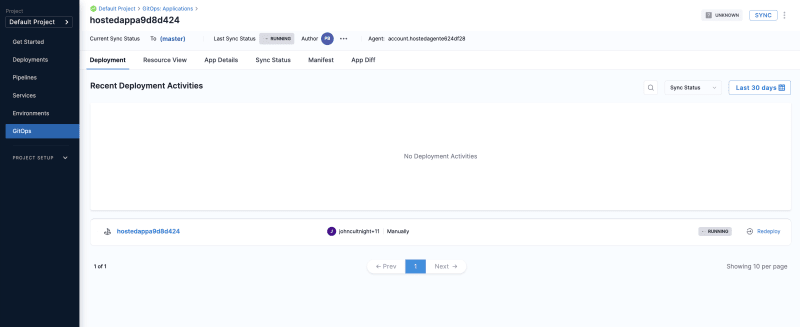
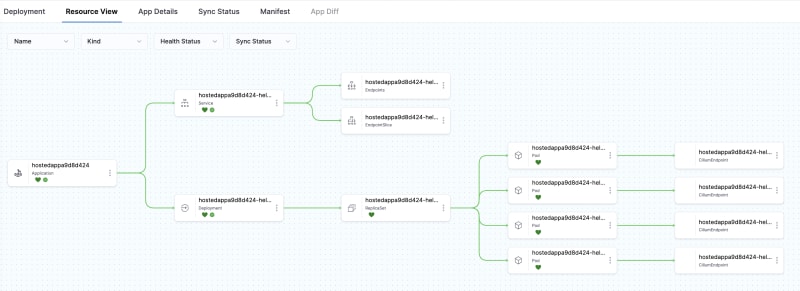
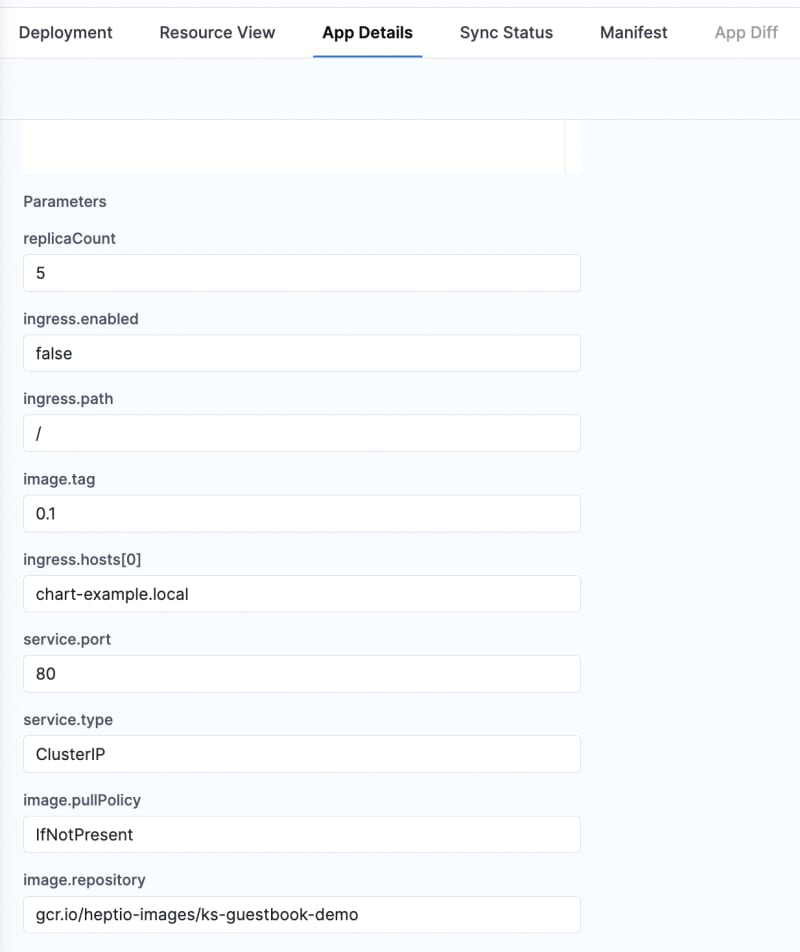
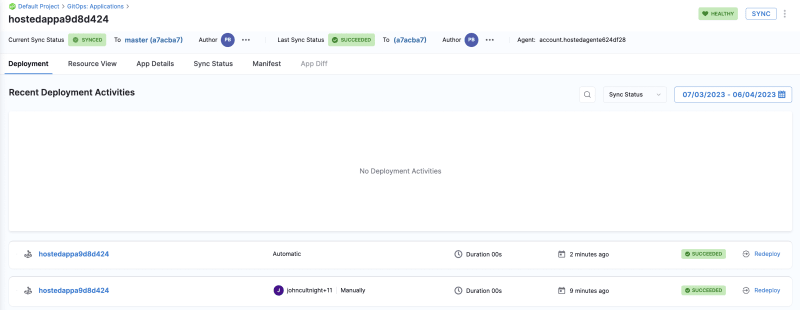
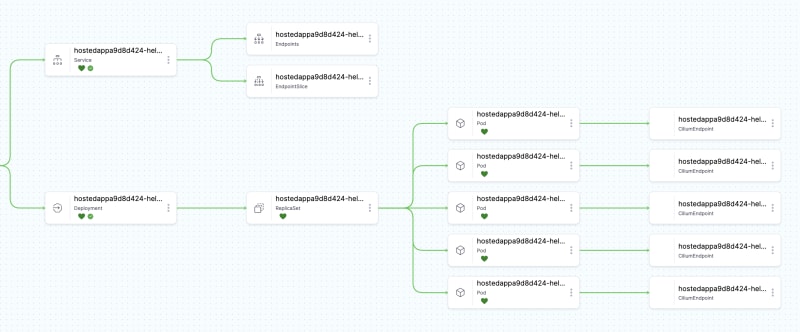
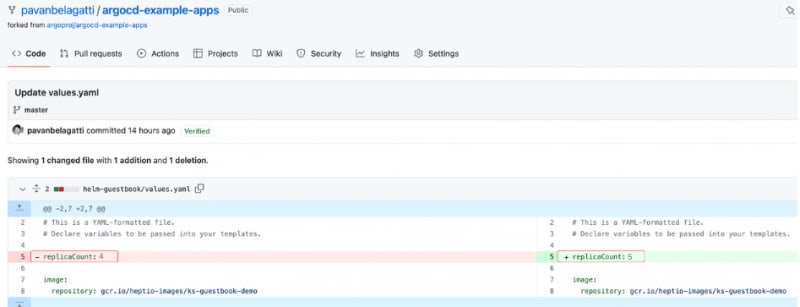



 马斯克在2017年的一次财报会上说过:"最难的产品不是车,而是制造车的工厂,发现像福特流水线那样的造车方式!"。事实上高度自动化的流水线是所有汽车制造工厂的核心引擎,能够大幅度提升造车产能同时降低成本,是企业的核心命脉!
马斯克在2017年的一次财报会上说过:"最难的产品不是车,而是制造车的工厂,发现像福特流水线那样的造车方式!"。事实上高度自动化的流水线是所有汽车制造工厂的核心引擎,能够大幅度提升造车产能同时降低成本,是企业的核心命脉!
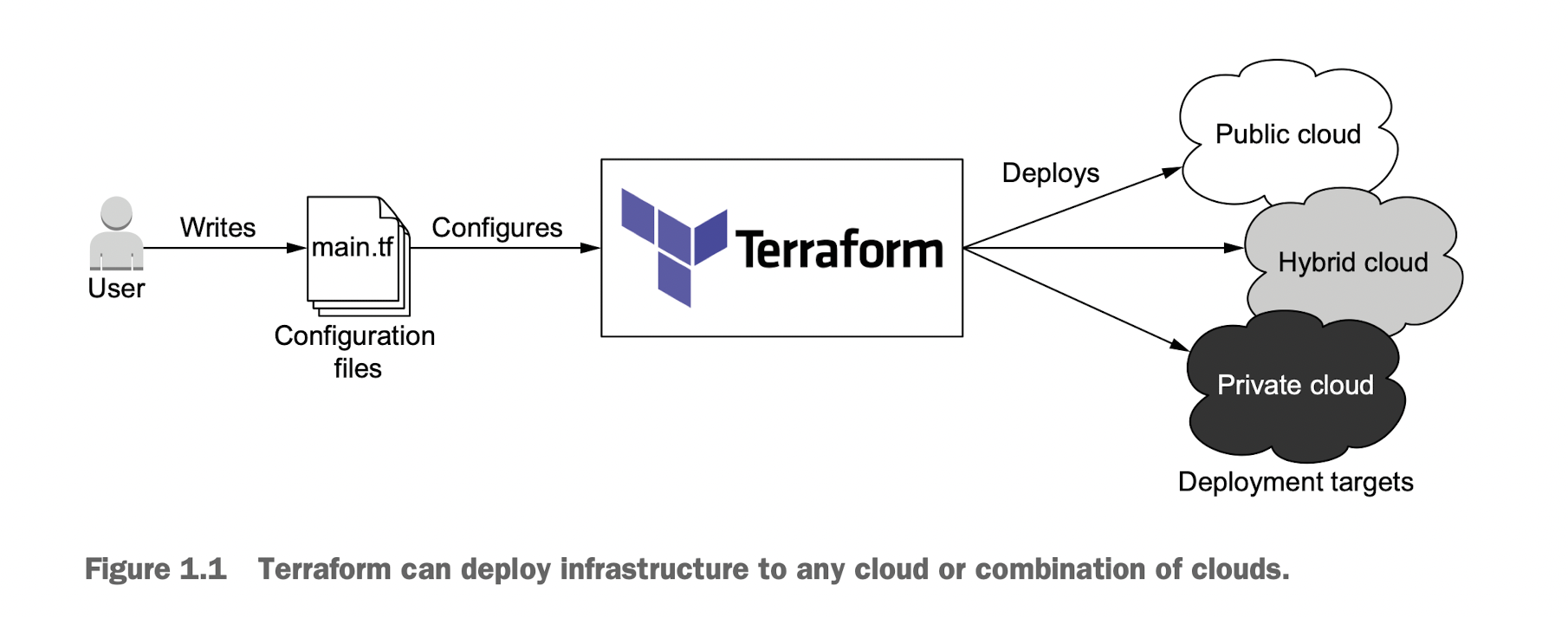
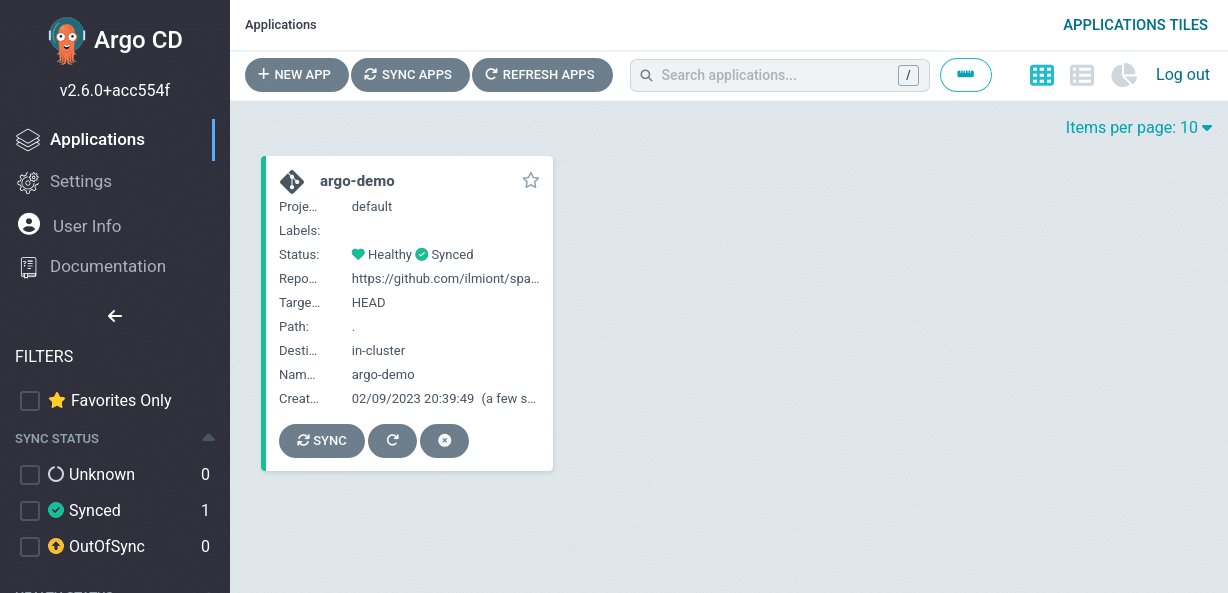
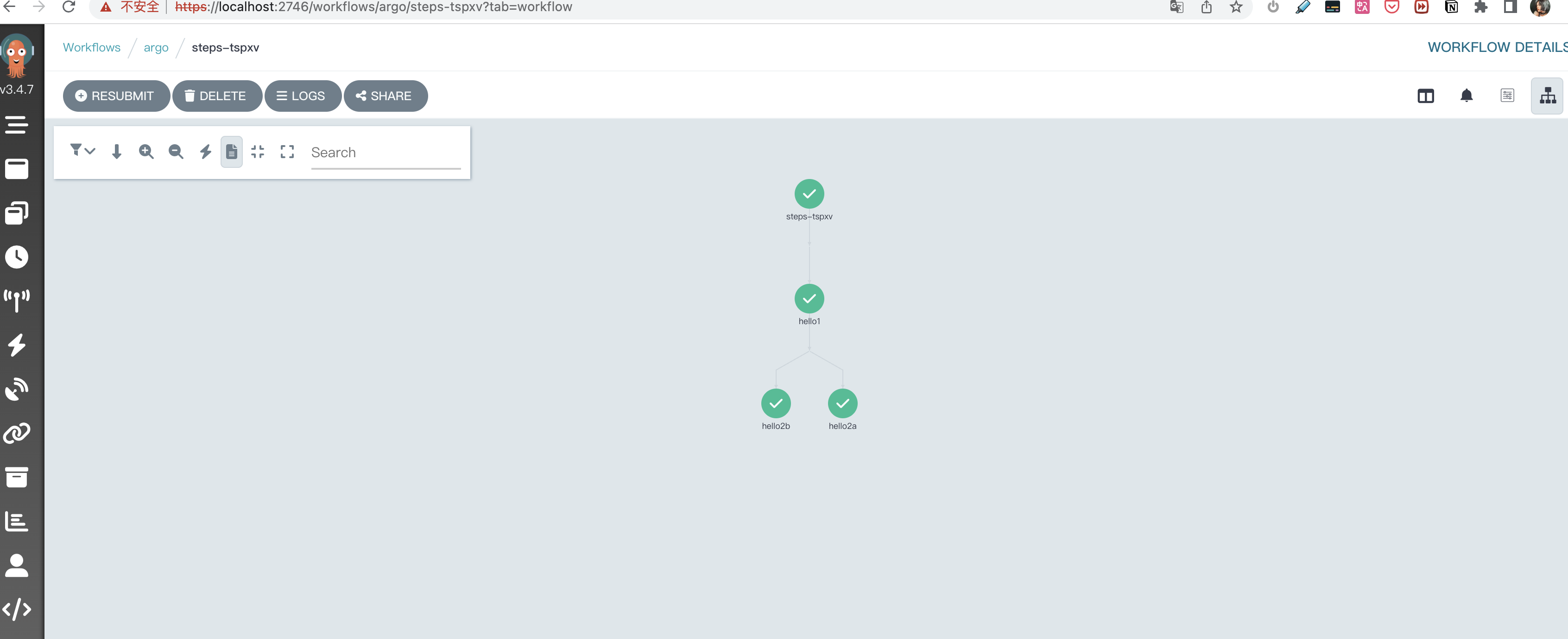
 CI/CD 工作流是指持续集成(Continuous Integration, CI)和持续交付/部署(Continuous Delivery/Deployment, CD)的过程。它是一种自动化软件开发实践,旨在加速软件的构建、测试和发布。CI/CD 工作流有助于提高开发团队的协作效率,降低错误风险,并确保软件质量。
CI/CD 工作流是指持续集成(Continuous Integration, CI)和持续交付/部署(Continuous Delivery/Deployment, CD)的过程。它是一种自动化软件开发实践,旨在加速软件的构建、测试和发布。CI/CD 工作流有助于提高开发团队的协作效率,降低错误风险,并确保软件质量。